/ infrastructure
Enterprise Secure Cloud Hosting
Won the RFP, designed and operated AWS + Cloudflare + Datadog for an enterprise client. From fragmented vendors with security incidents to unified ownership.
Impact
Problem
An enterprise client had a fragmented vendor structure: one vendor managed the website, another managed the server. A security incident occurred, but neither vendor took accountability and the root cause could not be traced. The site was unstable, with page load times of more than 5 seconds.
They issued an RFP for a single vendor to take full ownership of hosting, security, and maintenance. I led the RFP response, designed a unified architecture proposal, validated each requirement through rapid proof-of-concept, and won the bid.
My Role
Project Manager and Technical Lead, 2-person team (myself + 1 junior). Main point of contact for all technical requirements. Handled everything from RFP response to architecture design to daily operations. Mentored the junior member from basic support tasks to independently managing server maintenance and troubleshooting complex issues.
Key Decisions
-
Why WordPress + AWS instead of a modern platform?
The client's team was already familiar with WordPress. Migration to a new CMS would mean retraining, content migration risk, and SEO ranking disruption. With a 2-person team, choosing a mature ecosystem we knew deeply was more reliable than betting on something new. For hosting, we compared Cloudways, shared hosting, and VPS. AWS won on security and stability for an enterprise client that needed enterprise-grade SLAs.
-
How did you achieve 99.95%+ uptime for 3+ years?
Worked backwards from the SLA target. 99.95% means less than 21 minutes of downtime per month, planned maintenance only. This required: Multi-AZ RDS for database redundancy, automated failover, daily automated backups, real-time alerting via Datadog + CloudWatch, and multi-layer security (Cloudflare WAF + server firewall). Weekly Cloudflare security checks and monthly performance analysis caught issues before they affected uptime.
-
How did you handle security for an enterprise client?
Coordinated 6+ VAPT cycles (Vulnerability Assessment and Penetration Testing) with external vendors: scoping, testing, remediation, and re-validation. Cloudflare WAF rules were reviewed weekly. Implemented Cloudflare Zero Trust Access for secure admin access. CrowdStrike for endpoint protection. Zero security incidents over 3+ years.
-
How did you catch issues proactively?
Example: Datadog flagged a CPU spike between 8-11 PM every night. Correlated it with Cloudflare access logs and identified the source: an unauthorized SEO crawler (Screaming Frog) that the client had not approved. Updated WAF rules to block that user agent. CPU stabilized back to the normal 15-25% range. Without the Datadog + Cloudflare log correlation, this would have looked like a legitimate traffic spike.
Architecture
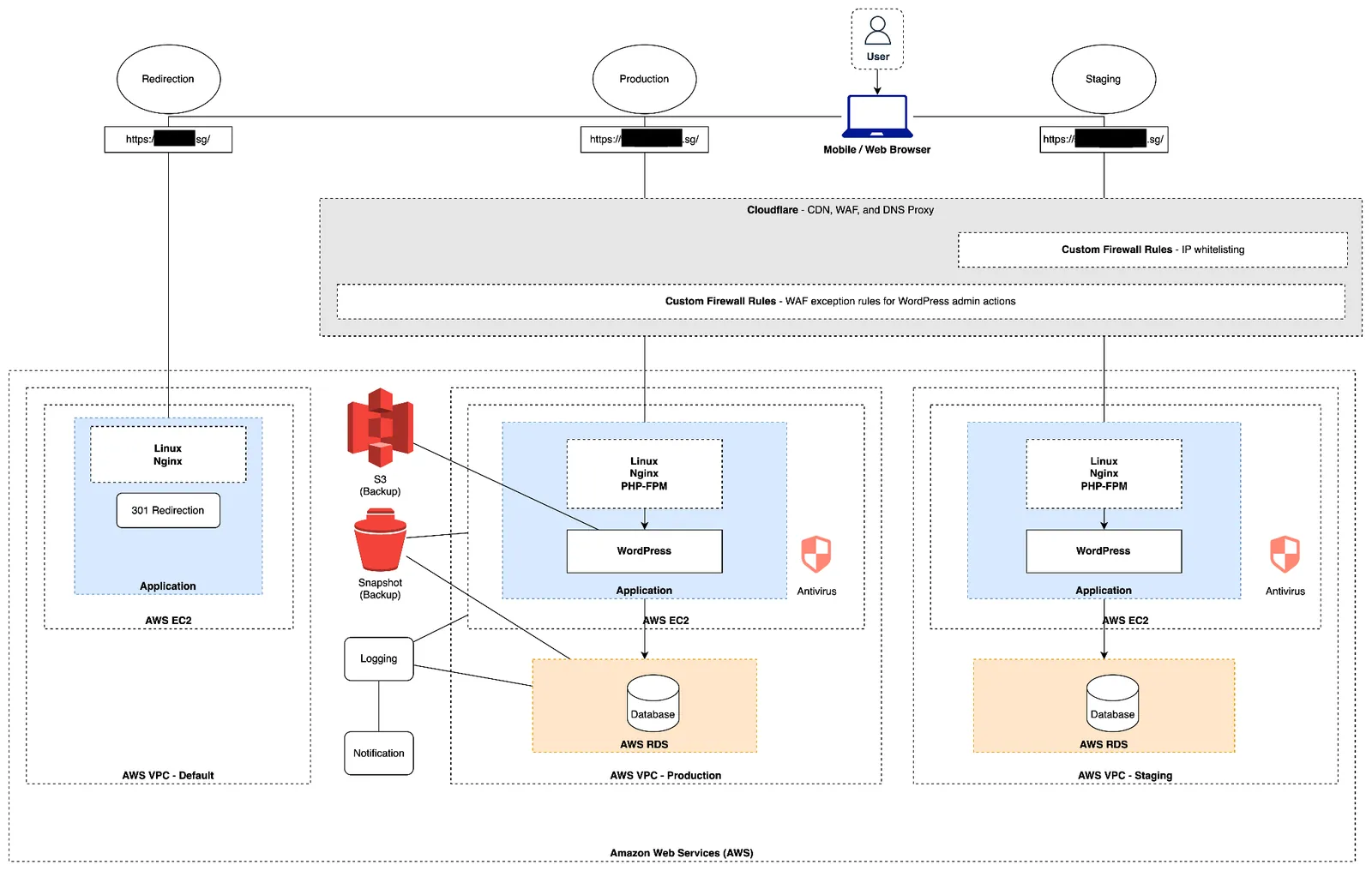
Users | v Cloudflare (Edge Layer) |-- CDN (static asset caching) |-- WAF (DDoS protection, bot management, custom rules) |-- DNS + SSL/TLS |-- Zero Trust Access (secure admin access) | v AWS (Compute + Data) |-- EC2 (Nginx + WordPress + Node.js) |-- RDS Multi-AZ (database redundancy + automated failover) |-- S3 (static assets, backups) |-- CloudFront (CDN origin) |-- Lambda (utility functions) |-- CloudWatch (infrastructure metrics + alarms) |-- VPC (network isolation) |-- Daily automated backups | v Monitoring + Reporting |-- Datadog APM (real-time application monitoring) |-- Monthly PDF report (4 pillars): | 1. Availability: uptime SLA tracking | 2. Performance: P90 server response, CPU/memory trends | 3. Security: WAF threats blocked, access log scanning | 4. Maintenance: WordPress core, plugin, OS patch log | v Security |-- CrowdStrike (endpoint protection) |-- 6+ VAPT cycles with external vendors |-- Weekly Cloudflare WAF rule reviews
Why This Matters for AI Systems
Operating a system at a 99.95% SLA for 3+ years taught me that production AI is not just about the model. The same patterns apply: monitoring and anomaly detection (Datadog + Cloudflare log correlation is the same pattern as LLM observability), graceful degradation (failover and fallback strategies), and proactive issue detection before users are affected.